The paper reads like a recent project, but it was actually written in 1991!
Wow! That’s almost 30 years ago! That ‘massive parallelism’ was tested on a PC and a higher-powered SUN Sparc workstation with a CPU running at 20Mhz. That’s not a typo.
Reading through the paper is quite interesting for me. In my previous job, I had several upgrade projects of systems that were 10-15 years old with very little documentation. My role of Solution Architect was actually closer to “Application Archaeologist’. It’s amazing to read an almost 30-year-old document and compare it to current solutions. Let’s check this paper out…
The McMasters website tags this as a masters paper by Emmanuel B. Aryee
The training set is very, very small, with 5 clean fillet images and 5 parasitic fillet images.
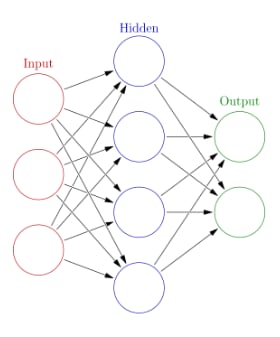
The neural net is 32 input neurons, 65 hidden neurons, and 2 output neurons. The image of the fish fillet is 512×512 initially, then reduced to 256×256. This is further sliced down to take only 32 pixels (0-255 greyscale normalized to 0-1) as input to the neural net. This is a very small network, and a very small set of images to use for training. The results show some accuracy in detecting a heavily infested fillet sample, which I believe the neural network could identify simply by seeing the short ‘bump’ in the image numbers where the dot of the worm is seen. For instance: 0,0,0,0,0,0,0,0.7,0.5,0,0,0,0,0,0,0 shows a short bump in values that indicates a worm. It could also represent a bone or edge since the network doesn’t have the input size to differentiate a line vs a spot.
Looking in the footnotes, I see a reference to commercial work from 3 years earlier: CANPOLAR INC., Toronto, Ontario, “Evaluation of Potential Automated Parasite Recognition Technology”, September 1988. There is also a reference to a trademarked system by CANPOLAR called Parasensor from 1990, and an actual commercial attempt with $2.2m funding that ran from 1996-1998 (source). I did not see any later commercial products. The master’s paper was likely a small project to see if the cutting edge 1990 AI techniques could improve the results of the 1988 version.

How does this compare with current technology and algorithms?
A recent IBM AI capstone project I completed using the concrete surface crack dataset consisting of 40,000 images at 227x227x3 pixels. The model used was the RESNET18 model, which has 18 layers and has already been trained on over a million images to identify common features in images. It also has an output layer that corresponds to 1000 image types. For the concrete crack example, the 1000 mode output layer is removed and replaced with a 2 node layer that indicates a binary classification of crack or no crack. This model is convolutional so it can shift the window over the image and detect the difference between a spot and an edge, resulting in better feature detection. The multiple layers increase the feature detection and the skip connections in the residual network eliminate the vanishing gradient problem that limited the 1991 solution to a shallow network. A potential solution to the image intensity and darkness could be multiple captures at different light levels, much like how HDR images are created. A modern-day solution to high-speed parasite detection is now possible.
The RESNET18 model can run on my $99 NVidia Jetson Nano that has a quad-core ARM processor running at 1.4Ghz and a 128 core NVidia GPU for model acceleration, all running at 10 watts maximum power. Clearly, 30 years of improving technology and algorithms have had a stunning impact on image recognition.

30 years is a long time between the optimism of the late 80s and current day AI implementations. Those years between are the topic for another time: The AI Winter.