
Sometimes the ‘factual’ data you are given is just bad. A project to categorize World Health documents using AI doesn’t yield expected results, and a deep dive into the data shows that the training document categorizations were often inaccurate. In several cases, documents classified under ‘water’ had zero keywords of ‘water’, ‘liquid’, ‘thirst’, or ‘drought’.
This post is about my Microsoft AI Capstone project and the importance of checking both the training data and labels that are used to evaluate the AI model. Bottom line: Don’t ever assume the data classification (labelling) is correct.
The final course in the Microsoft Professional Program in Artificial Intelligence was a capstone project designed to prove your understanding of the previous courses. The goal was to design a model that could classify documents into multiple relevant categories. Over 18,000 documents from the World Bank were provided, along with categories for each document. The only hint was to use a multi-label classifier such as the sklearn OneVsRestClassifier. Another 18,000 test documents were provided without categories, and your model had the evaluate each document and assign 0-n categories to each document. The final category predictions from the model were uploaded to the challenge site and scored.
KyungA and I worked independently on the challenge with only limited general discussions about our progress. This was how we approached all the coding challenges, and was quite interesting, as we both like to compete and WIN! Our scores on the challenge were well above the minimum requirement but not quite to a maximum score. After submitting scores, I was still disappointed that the trained model maxed out at about 79% match, and decided to try other algorithms. None of the algorithms were standouts, so I started to look at the data.
Document count:
18,686 training documents with category labels.
18,698 test documents (no labelling). Your model must predict the category labels.
The 24 categories and number of documents in each category:
| category | number_of_documents | |
| 0 | information_and_communication_technologies | 784 |
| 1 | governance | 1663 |
| 2 | urban_development | 1395 |
| 3 | law_and_development | 2418 |
| 4 | public_sector_development | 2642 |
| 5 | agriculture | 1174 |
| 6 | communities_and_human_settlements | 1607 |
| 7 | health_and_nutrition_and_population | 3397 |
| 8 | culture_and_development | 306 |
| 9 | social_protections_and_labor | 2290 |
| 10 | international_economics_and_trade | 2419 |
| 11 | conflict_and_development | 819 |
| 12 | science_and_technology_development | 875 |
| 13 | rural_development | 1793 |
| 14 | poverty_reduction | 2580 |
| 15 | social_development | 1614 |
| 16 | education | 2323 |
| 17 | transport | 1542 |
| 18 | gender | 1066 |
| 19 | infrastructure_economics_and_finance | 335 |
| 20 | energy_and_environment | 3276 |
| 21 | finance_and_development | 8805 |
| 22 | macroeconomics_and_growth | 7959 |
| 23 | water | 1619 |
There are 24 categories. What struck me was that the labels could be quite subjective and the descriptions overlapped. Seven were development related and four were finance related. When I looked at the training labels, they showed relationships between the labels. This is one reason for using the OneVsRestClassifier, which looks not just at the document, but the scoring of that document in each category. A document labelled as ‘finance_and_development’ is very likely to also be in ‘macroeconomics_and_growth’.
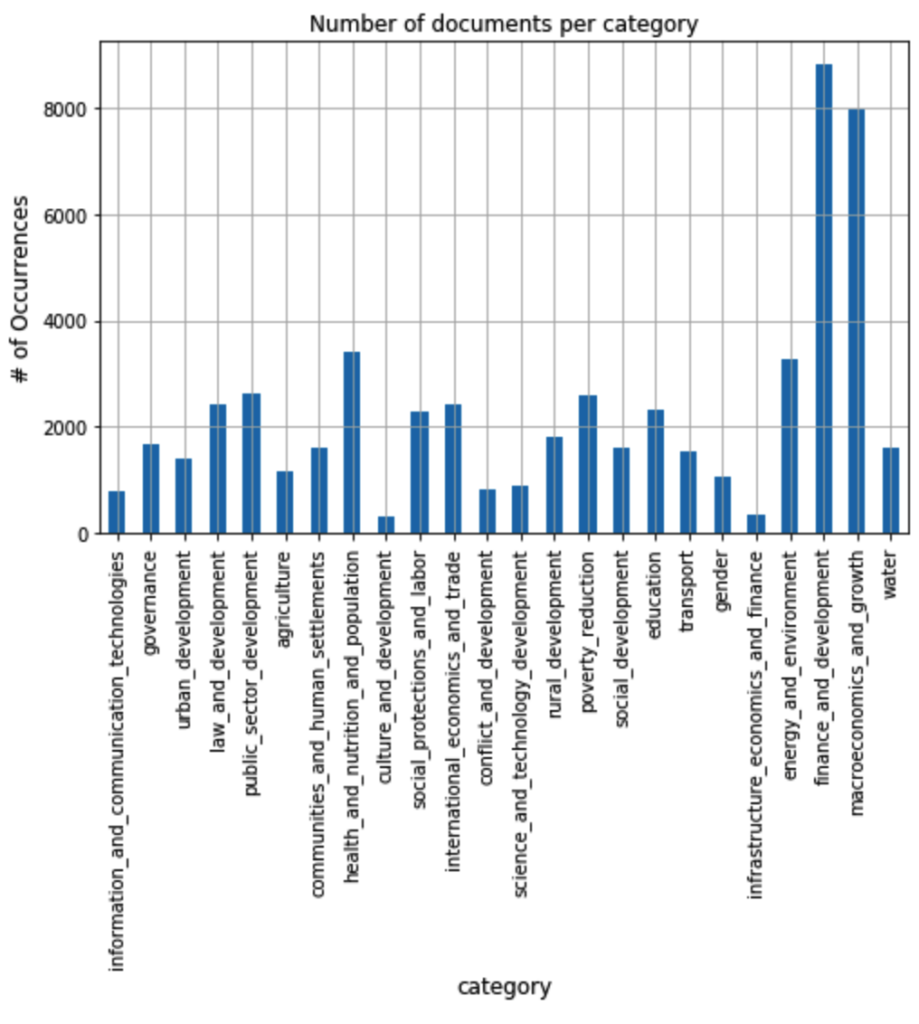
The category assignment showed why it was difficult for the model to achieve a high score. People assigning categories after reading each document would have different results because of the category overlap. A ML model that looks at words and wordcounts in the document will score below a human. Tricks like stemming and lemmatizing (used, using, uses -> use), word vectors (boy girl male female are close vectors), and dropping common words helped, but still not to human level accuracy.
So is that just as good as it gets?
I had an idea to create a list of overweight words that might help categorization. For the water category, I could assign higher weights to ‘water’, ‘drought’, ‘wells’, etc., which could theoretically increase the score. If a person found those words repeatedly in a document they would likely assign it to the water category.
Now for the shock…
I wrote some Python code to do a wordcount on ‘water’ for each training document that was assigned to the water category. The results showed that some documents had 30-60 mentions of water, but some documents had almost none. I tweaked the code to report water category documents with three or less occurrences of water. Here are the results for the first 1100 documents:
Documents classified as water but with 3 or less instances of ‘water’:
DocNumber: category wordcount
16: water=1 count: 1
31: water=1 count: 1
100: water=1 count: 2
137: water=1 count: 2
289: water=1 count: 1
349: water=1 count: 1
431: water=1 count: 2
492: water=1 count: 2
629: water=1 count: 0
659: water=1 count: 0
724: water=1 count: 3
768: water=1 count: 3
810: water=1 count: 1
875: water=1 count: 1
928: water=1 count: 0
935: water=1 count: 0
1006: water=1 count: 0
1037: water=1 count: 3
1081: water=1 count: 0
1084: water=1 count: 1Wow!! How can a document be classified as about water, but have zero occurrences of the word water? That’s just not possible. It’s clear from this that many documents are likely misclassified. This is the training data we use for the model, so the model never has a chance.
Ok, so let’s dive into a few documents to verify our hypothesis.
Lets look at the documents in rows 629, 928, and 1081 that have zero occurrences of water.
Document from row 629 is Worldbank document #66093
I should note here that the training and test data only includes the first 20k characters of each document to reduce the total data size. Even with this reduction, the training and test files are 326mb each, and about 160mb when cleaned of short words, spacing, punctuation, and non-words.
Searching the full text shows two mentions of water, so we did miss a bit from only having the first 20k of the document. Reading the document though tells me it is not water-related. So why would Microsoft think it is?
Let’s look at the metadata on the document page. Under ‘Historic Topics’ it is marked as ‘Water Resources’.
Topics
Education,Jobs,Urban Rail,Information and Communication Technologies,Poverty,
Historic Topics
Private Sector Development,Information and Communication Technologies,Industry,Water Resources,Finance and Financial Sector Development,
Historic SubTopics
Labor Markets,Information Technology,Educational Sciences,Railways Transport,Inequality,
The Microsoft provided category labels are:
information_and_communication_technologies, finance_and_development, macroeconomics_and_growth, water
Not exact, but I think Microsoft must have downloaded the document set and the categories from the World Bank site and not checked the category accuracy.
Let’s look at the next ‘zero water’ document:
Row 928 is WorldBank document 72840
Historic Topics
Information and Communication Technologies,Communities and Human Settlements,Water Resources,Private Sector Development,
The Microsoft provided category labels are:
information_and_communication_technologies, communities_and_human_settlements, finance_and_development, water
(A match except for ‘Private Sector Development’ vs ‘finance_and_development’)
Wow! The categories are an almost exact match to the training labels.
Now the third ‘zero water’ document…
Row 1081 is WorldBank document 94102
Historic Topics
Water Resources,Social Protections and Labor,Industry,International Economics and Trade,Macroeconomics and Economic Growth,Finance and Financial Sector Development,
The Microsoft provided category labels are:
social_protections_and_labor, international_economics_and_trade, finance_and_development, macroeconomics_and_growth, water
(only ‘Industry’ is missing, and it is not one of the 24 training labels.)
So, we see the source of the training data categories. They don’t match exactly, so let’s research the World Bank categorization.
Browse journal documents by topic:
The categories have two levels, such as ‘Water Resources::Flood Control’. That doesn’t explain the differences between the training data categories and the WorldBank website categories. It looks like only a subset of the categories was included in the training data, and that some dropped categories were mapped to similar categories.
Conclusion:
- The training categories are pulled from the World Bank site, and they are not always accurate.
- Having only the first 20k characters in each document can reduce the accuracy of the model categorization.
- The model can never achieve optimal accuracy if the training data is not accurate.
Also:
Knowing the source of the categories means we could search the World Bank site for each test document and know what our model should predict. This is CHEATING, but it would be interesting to see the reaction of the instructors when the tops scores all hit a ceiling at around 0.84 and then suddenly we get results that are 0.98!
The best way to do that?
- Extract the correct categories for each test document from the World Bank site.
- Train the model on the TEST data and categories. (This is overfitting and of course, cheating)
- Run the model on the TEST data to generate model predicted categories for the documents.
- Submit the model predicted categories for scoring.
- Submit the trained model for verification.
This part is really interesting because trained models are essentially a black box. The inner workings can’t be examined to show how the model was trained. And that means you would just have a frustrated instructor that is sure you cheated but can’t prove it. You are actually demonstrating one of the challenges of analyzing AI models!
So that’s it. The capstone was a great challenge, and I learned even more after diving into the data. It’s difficult and dangerous to use an AI model without first truly understanding your data.
(That photo of the dried fish? It’s from the Salton Sea, which is a sad story of resource misuse.)